1. Introdução
Nesse projeto eu analisei uma base contendo dados de 15000 funcionários de uma dada empresa para realizar uma previsão de turnover. Ou seja, eu analisei a rotatividade de funcionários com o objetivo de descobrir os principais motivos que influenciam um funcionário dentro da empresa a sair dela.
Para isso eu usei um arquivo .ipynb e utilizei as bibliotecas Pandas, NumPy, MatPlot, DataPrep e SKLearn.
2. Análise Pré Exploratória
Para começar essa fase eu fiz uma análise da base de dados, e notei que haviam oito variáveis numéricas e duas variáveis escritas. Após isso eu criei um relatório automatizado da biblioteca dataprep.eda utilizando os dados da nossa base para estudar melhor individualmente cada variável.
- satisfaction_level
- last_evaluation
- number_project
- average_montly_hours
- time_spend_company
- Work_accident
- left
- promotion_last_5years
- sales
- salary
3. Melhorando a Base de Dados
Observando a base de dados eu verifiquei que haviam alguns dados que podiam ser alterados para quando chegasse a hora de criar as máquinas preditivas.
Então depois de analisar a variável 'sales' eu notei que o nome da variável estava errado, pois 'sales' já era uma das categorias contidas dentro da variável então eu mudei o nome da variável para 'department'. E ainda na variável 'department' eu juntei as categorias 'IT' e 'support' na categoria 'technical', visto que essas três categorias poderiam ser resumidas em apenas uma.
Eu também decidi trocar as variáveis escritas por variáveis numéricas para que o algoritmo de Machine Learning pudesse alcançar uma acurácia maior no fim do projeto. Para isso eu realizei um processo de One Hot Encoding manual.
Primeiro eu criei uma variável para cada categoria dentro de 'department', armazenando o valor 1 caso a categoria em questão seja a do funcionário e o valor 0 caso não seja a categoria referente do funcionário. Depois fiz o mesmo processo para a variável 'salary'. E então excluí as variáveis 'department' e 'salary' para manter apenas as variáveis numéricas na base de dados.
Dessa forma foram criadas as seguintes variáveis:
- department_RandD
- department_accounting
- department_hr
- department_management
- department_marketing
- department_product_mng
- department_sales
- department_technical
- salary_high
- salary_medium
- salary_low
4. Seleção das Melhores Variáveis
Após a criação de todas as variáveis numéricas, eu realizei uma RFE (Eliminação Recursiva de Atributos) utilizando um modelo de Regressão Logística que selecionou as 10 melhores variáveis entre as 19 disponíveis para criar uma máquina preditiva eficiente. Que foram:
- satisfaction_level
- last_evaluation
- time_spend_company
- Work_accident
- promotion_last_5years
- department_RandD
- department_hr
- department_management
- salary_high
- salary_low
5. Criação de Máquinas Preditivas
Com as principais variáveis devidamente escolhidas eu criei a primeira máquina preditiva utilizando o método de Regressão Logística porém ela alcançou uma acurácia relativamente baixa de 77,1%. Então eu criei uma segunda máquina preditiva, dessa vez utilizando o método de Random Forest que por sua vez teve uma acurácia de 97,8%. Eu ainda tentei utilizar uma máquina de XGBoost com 5000 árvores que chegou à um resultado de 97,7% de acurácia.
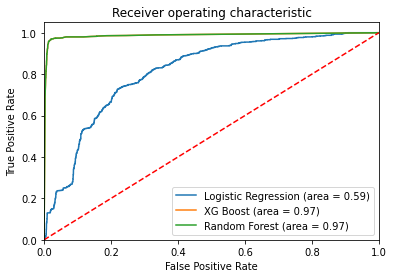
6. Análise das Máquinas Preditivas
Observando a confusion matrix da máquina que utiliza Logistic Regression eu notei que ela tem uma taxa de 3468 acertos para 1032 erros.

Já as máquinas de Random Forest e XG Boost erraram 10 vezes menos do que a Logistic Regression. Atingindo uma taxa de 4403 acertos para 97 erros.
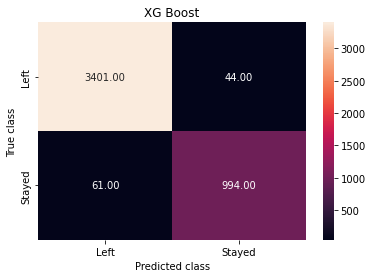
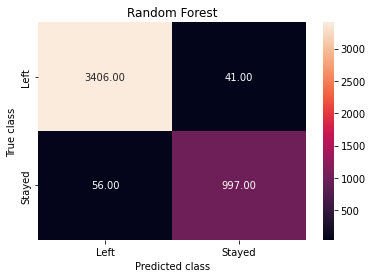
7. Considerações finais
Para o fim da análise eu decidi que a máquina preditiva de Random Forest foi a melhor, já que ela atingiu uma taxa de acurácia 0,1% maior que a XG Boost, além de ser uma estrutura mais simples.
E utilizando o modelo de classificação Random Forest, as características mais importantes que irão influenciar a saída do funcionário da empresa em ordem crescente são:
1. department_management: 0.25%
2. promotion_last_5years: 0.26%
3. department_hr: 0.27%
4. department_RandD: 0.32%
5. salary_high: 0.68%
6. salary_low: 1.23%
7. Work_accident: 1.51%
8. last_evaluation: 18.27%
9. time_spend_company: 26.41%
10. satisfaction_level: 50.80%